

Flink-词频统计
Flink on k8s部署
前提要确保k8s正常运行
从极客时间-Flink核心技术与实战中将lab-2-install-flink-cluster/kubernetes-deploy/session-mode文件夹上传到服务器,进入到session-mode路径下操作:
# 1.创建Flink Conf Configmap资源
kubectl create -f flink-configuration-configmap.yaml
# 2.创建JobManager Service
kubectl create -f jobmanager-service.yaml
# 3.创建JobManager和TaskManager Deployment
kubectl create -f jobmanager-session-deployment.yaml
kubectl create -f taskmanager-session-deployment.yaml
# 4.创建Restful服务,暴露Flink Web UI端口
kubectl create -f jobmanager-rest-service.yaml将流量从宿主机转发到 Flink 的 Pod,并且可以让宿主机上的所有网络接口都能访问。
kubectl port-forward --address 0.0.0.0 deployment/flink-jobmanager 8081:8081保持终端常开,此时在本机可访问http://<宿主机IP>:8081可以访问flink的ui界面。
词频统计程序
在本地IDEA编写词频统计程序
package com.ruoyi.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class SocketWordCount {
public static void main(String[] args) throws Exception {
// 1. 获取 Flink 流处理的执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 连接到 socket 数据源,监听 服务器 的 9999 端口
// 从这个端口输入的每一行数据都会被当作一个字符串
DataStream<String> text = env.socketTextStream("192.168.1.221", 9999);
// 3. 执行核心的 WordCount 逻辑
DataStream<Tuple2<String, Integer>> wordCounts = text
// 3.1. 将每一行文本拆分成单词
.flatMap(new Splitter())
// 3.2. 按照单词 (key) 进行分组
.keyBy(value -> value.f0)
// 3.3. 对每个单词的数量进行累加求和
.sum(1);
// 4. 将结果打印到标准输出 (在 TaskManager 的日志中)
wordCounts.print();
// 5. 启动任务执行,给作业起个名字
env.execute("Socket Window WordCount");
}
/**
* 自定义一个 FlatMapFunction,用于将一行文本拆分成多个 (单词, 1) 的元组
*/
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word: sentence.split(" ")) {
out.collect(new Tuple2<>(word, 1));
}
}
}
}DataStream<String> text = env.socketTextStream("192.168.1.221", 9999);配置数据源,这个地址要写宿主机能访问到的地址
添加依赖到xml中,依赖的版本要与集群的flink镜像版本统一。
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.11.1</flink.version>
<scala.binary.version>2.11</scala.binary.version>
</properties>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>执行打包,在target目录下可以找到.jar文件
mvn clean package提交作业到Flink集群并查看结果
启动数据源
因为程序在监听宿主机:9999,我们需要连接到该端口发送数据,新开终端在宿主机运行:
nc -lk 9999- 一定要在提交作业前启动数据源!
- 之后我们在这个终端输入的信息都会被发送到9999端口
提交作业
在flink的web-ui,即http://<宿主机IP>:8081,选择Submit New Job将jar包上传。
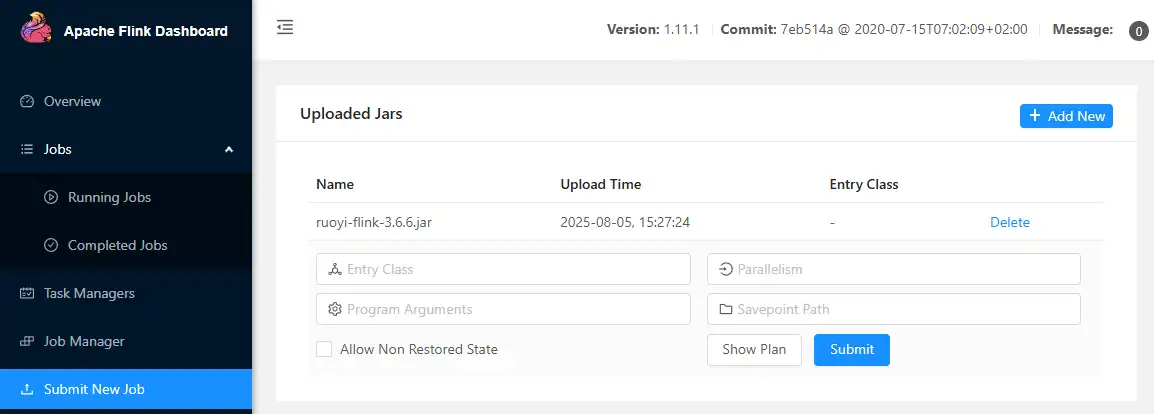
上传作业
- Entry Class(入口类): 包名.类名
- Parallelism (并行度)
- Program Arguments (程序参数) :需要接收的命令行参数,没有留空
- Savepoint Path (保存点路径): 用于从一个指定的快照恢复作业状态 ,新作业留空
成功可在Running Jobs看到相关信息。
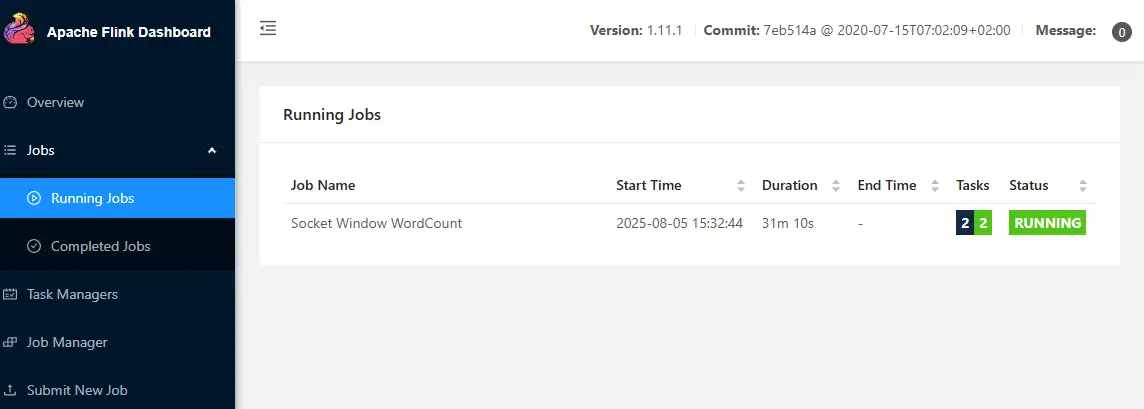
作业运行中
查看实时结果
程序的结果 会输出到执行这个任务的 TaskManager 的标准输出 (stdout) 日志里。
找到TaskManager Pod
$ kubectget pods
NAME READY STATUS RESTARTS AGE
flink-jobmanager-7d6f8c9656-mctgd 1/1 Running 0 30h
flink-taskmanager-7b8c6bdc68-f96rj 1/1 Running 0 30h
flink-taskmanager-7b8c6bdc68-nbbkr 1/1 Running 0 30h查看实时日志
kubectl logs -f flink-taskmanager-7b8c6bdc68-f96rj这个时候我们在nc终端里输入信息,在日志中可以实时查看词频统计
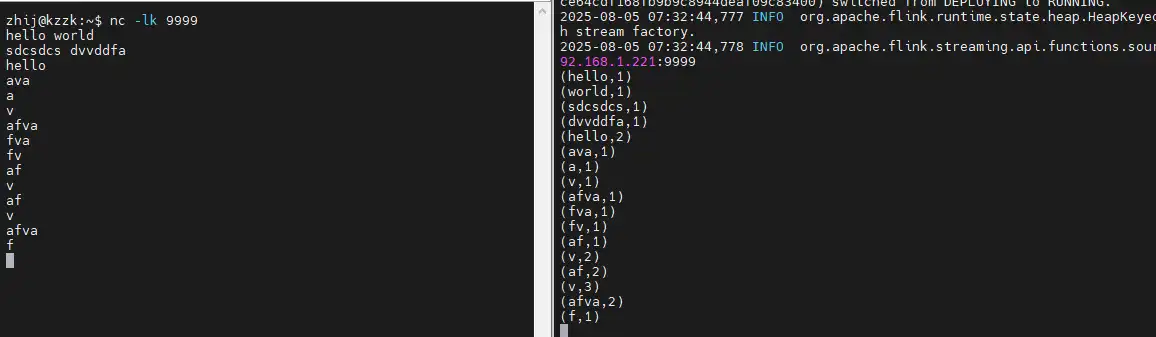
实时词频统计